"How's that movie?" - Collaborative filtering with FastAI
Build a state-of-the-art movie recommendation system with just 10 lines of code

Recommender systems are at the core of pretty much every online service we interact with. Social networking sites like Facebook, Twitter and Instagram recommend posts you might like, or people you might know. Video streaming services like YouTube and Netflix recommend videos, movies or TV shows you might like. Online shopping sites like Amazon recommend products you might want to buy.
Collaborative filtering is perhaps the most common technique used by recommender systems.
Collaborative filtering is a method of making predictions about the interests of a user by collecting preferences from many users. The underlying assumption is that if a person A has the same opinion as a person B on an issue, A is more likely to have B's opinion on a different issue than that of a randomly chosen person. - Wikipedia
The librec Java library provides over 70 different algorithms for collaborative filtering. In this post however, we'll implement a relatively new technique called neural collaborative filtering.
The MovieLens 100K Dataset
The MovieLens 100K dataset is a collection of movie ratings by 943 users on 1682 movies. There are 100,000 ratings in total, since not every user has seen and rated every movie. Here are some sample ratings from the dataset:
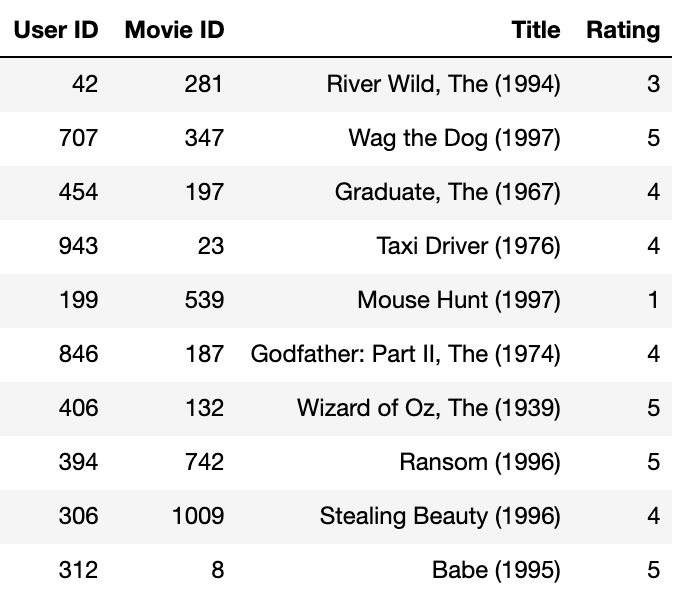
Every user is given a unique numeric ID (ranging from 1 to 943), and each movie is given a unique numeric ID too (ranging from 1 to 1682). User's ratings for movies are integers ranging from 1 to 5, with 5 being the highest.
Our objective here is to build a model that can predict how a user would rate a movie they haven't already seen, by looking at the movie ratings of other users with similar tastes.
System Setup
If you want to follow along and run the code as you read, you can clone this notebook, install the required dependencies using conda, and start Jupyter by running the following commands on the terminal:
pip install jovian --upgrade # Install the jovian library
jovian clone 5bc23520933b4cc187cfe18e5dd7e2ed # Download notebook
cd movielens-fastai # Enter the created directory
jovian install # Install the dependencies
conda activate movielens-fastai # Activate virtual environment
jupyter notebook # Start Jupyter
Make sure you have conda installed before running the above commands. You can also click on the "Run on Binder" button at the top to start a Jupyter notebook server hosted on mybinder.org instantly.
Preparing the Data
You can download the MovieLens 100K dataset from this link. Once downloaded, unzip and extract the data into a directory ml-100k next to the Jupyter notebook. As described in the README, the file u.data contains the list of ratings.
On Linux and Mac, you can simply run the follwing cell to download and extract the data:
# Download and extract the data (only for Linux and Mac)
!rm -rf ml-100k ml-100k.zip
!wget -q http://files.grouplens.org/datasets/movielens/ml-100k.zip
!unzip -q ml-100k.zip
!ls ml-100kallbut.pl u1.base u2.test u4.base u5.test ub.base u.genre u.occupation
mku.sh u1.test u3.base u4.test ua.base ub.test u.info u.user
README u2.base u3.test u5.base ua.test u.data u.item