!pip install pymagnitude git+https://github.com/huggingface/pytorch-pretrained-BERT.git -q%matplotlib inline
%config InlineBackend.figure_formats = ['svg']
import random
import sys
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import regex as re
from pymagnitude import Magnitude
from pytorch_pretrained_bert import BertTokenizer, BertForSequenceClassification, BertAdam
from sklearn.metrics import classification_report
from tqdm import tqdm, tqdm_notebook
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import Dataset, DataLoader, Subset
from torch.utils.data.dataset import random_split
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
from IPython.core.display import display, HTML
from google_drive_downloader import GoogleDriveDownloader as gdd
tqdm.pandas()
# If the machine you run this on has a GPU available with CUDA installed,
# use it. Using a GPU for learning often leads to huge speedups in training.
# See https://developer.nvidia.com/cuda-downloads for installing CUDA
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
deviceFine-Tuning BERT for Text Classification
While transfer learning has had a huge impact on image-based deep learning tasks, transfer learning is still a relatively new concept in NLP. The idea is that you first train a large model on a huge amount of data, and then you fine-tune the model on a smaller subset of data.
For example, we can train a large model on all of Wikipedia, then fine-tune our model on blog posts about statistics in order for our model to be able to identify the names of people in the blog posts about statistics. The model is able to leverage general understanding of language from Wikipedia to the specific task of identifying people in statistics blog posts.
The architecture of BERT is similar, and potentially the next iteration of. The architecture of the GPT-2. The GPT-2 of course uses OpenAI's Transformer, however the model can only look foward when predicting the next word in a sequence. That is to say that is is not bidirectional. Therefore, the GPT-2 model is more suited just as a language model for generating text than it is as a text classifier. If we want to build a solid text classifier, we should hope that we are able to consider both words before and after when looking at the text.
BERT is a masked language model. 15% of the input words are masked, or replaced by a special mask token. For every masked word, the model tries to use the output of the masked word to predict what the word is.
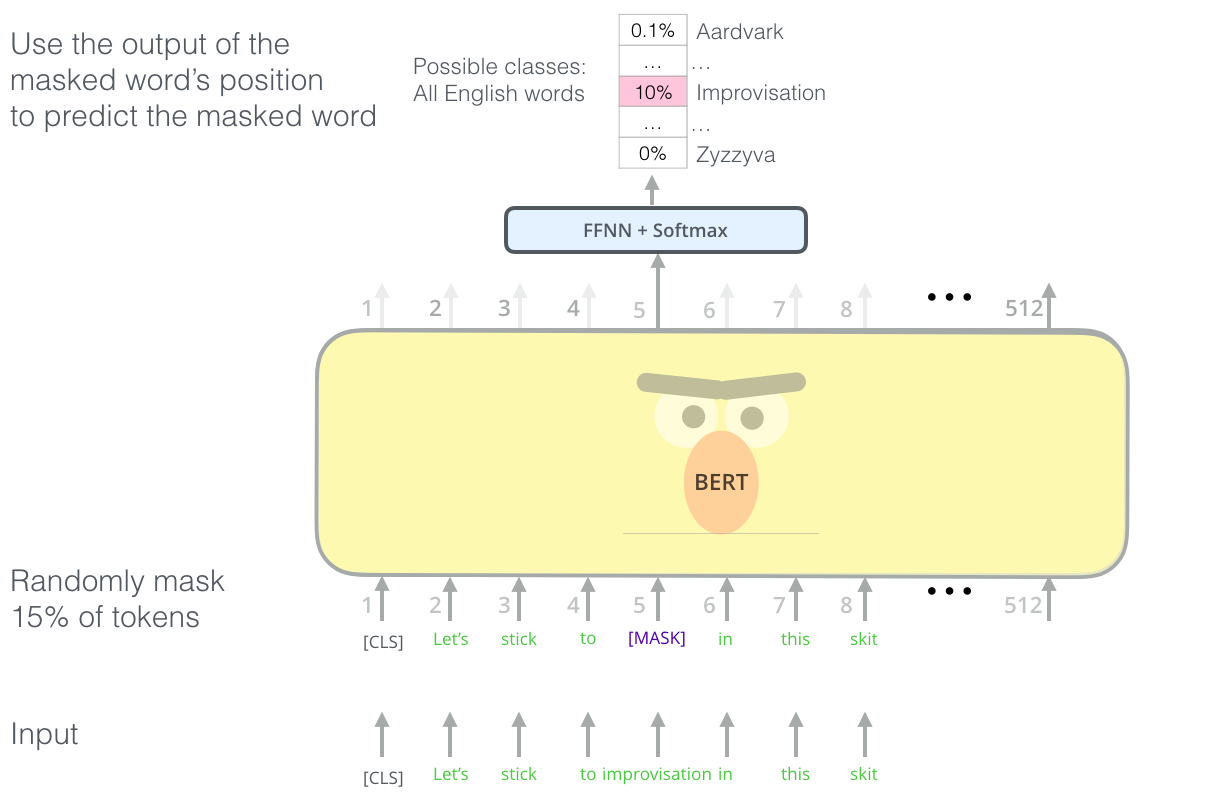
BERT can be setup to perform a number of NLP tasks such as text classification.
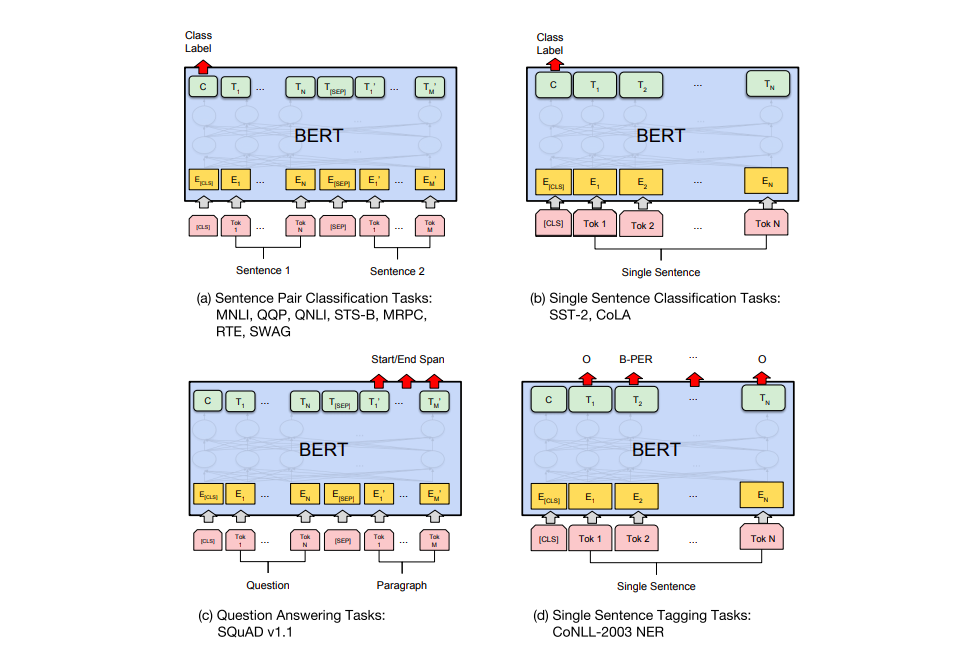
- Great blog post on BERT and the source of illustrations: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning).
Download the training data
DATA_PATH = 'data/imdb_reviews.csv'
if not Path(DATA_PATH).is_file():
gdd.download_file_from_google_drive(
file_id='1zfM5E6HvKIe7f3rEt1V2gBpw5QOSSKQz',
dest_path=DATA_PATH,
)